Informed decision-making often hinges on extracting insights from documents and data. However, when handling sensitive information, privacy concerns become paramount. LangChain, in conjunction with the OpenAI API, empowers you to analyze your local documents without the necessity of uploading them online.
This is accomplished by maintaining your data locally, employing embeddings and vectorization for analysis, and executing processes within your own environment. It’s important to note that OpenAI does not utilize data provided by customers through their API for the purpose of training their models or enhancing their services.

Preparing your environment
To ensure a smooth setup and avoid any conflicts in library versions, follow these steps to create a new Python virtual environment. Once that’s done, use the terminal command below to install the necessary libraries:
pip install langchain openai tiktoken faiss-cpu pypdfHere’s a breakdown of the purpose of each library in your setup:
- LangChain: This library will be your go-to tool for creating and managing linguistic chains, facilitating text processing and analysis. LangChain offers modules for tasks like document loading, text segmentation, embeddings, and vector storage.
- OpenAI: You’ll utilize the OpenAI library to execute queries and retrieve results from a language model, enabling you to harness the power of advanced natural language processing.
- tiktoken: This library serves the vital role of counting tokens (text units) within a given text. This functionality is crucial when working with the OpenAI API, as it charges based on the number of tokens processed. tiktoken helps you keep track of your token consumption.
- FAISS: FAISS comes into play for creating and managing a vector store, offering rapid retrieval of similar vectors based on their embeddings. This is essential for various text similarity and clustering tasks.
- PyPDF: PyPDF is a valuable addition to your toolkit, enabling the extraction of text from PDF documents. It simplifies the process of loading PDF files and extracting their textual content for further analysis.
Once you’ve successfully installed these libraries, your environment is now properly configured and ready for your document analysis endeavors.
Getting an OpenAI API key
When making requests to the OpenAI API, it’s essential to include an API key as part of the request. This key serves as a means of verification, enabling the API provider to confirm that the requests originate from a valid source and that you possess the required permissions to access its functionalities. To obtain an OpenAI API key, follow these steps:
- Access the OpenAI Platform:
- Go to the OpenAI platform on their website.
- Access Your Account Profile:
- If you have an OpenAI account, log in. Once logged in, locate your account profile, usually found in the top-right corner of the platform.
- View API Keys:
- Within your account profile, there should be an option to “View API keys.” Click on this option to access the API keys page.
- Create a New Secret Key:
- On the API keys page, you’ll find a button labeled “Create new secret key.” Click on it.
- Provide a Name for Your Key:
- Give your new API key a descriptive name to help you identify its purpose or usage.
- Generate the Key:
- After naming your key, proceed to create it by clicking the “Create new secret key” button once more. OpenAI will generate a unique API key for you.
- Copy and Store Securely:
- Once generated, ensure you copy the API key and store it securely. This key contains sensitive information and should be handled with care. For security reasons, OpenAI won’t display it again through your account. If you ever misplace or lose this secret key, you’ll need to create a new one.
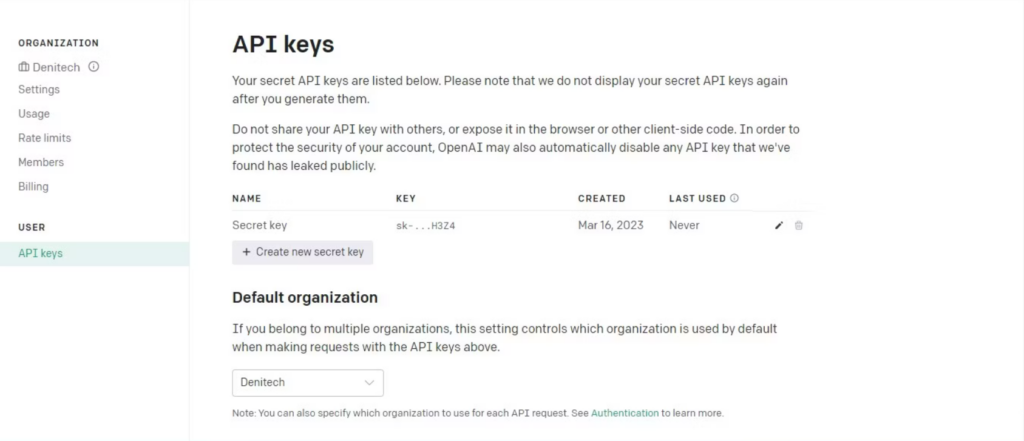
By following these steps, you will obtain a valid OpenAI API key that you can utilize to authenticate your requests to their services. It’s vital to keep this key secure and refrain from sharing it publicly, as it grants access to OpenAI’s capabilities and may result in charges based on your usage.
Importing the required libraries
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAIIn order to utilize the libraries that have been installed in your virtual environment, it’s necessary to import them. Take note that you import the required dependency libraries from LangChain. This enables you to access and leverage the specific functionalities provided by the LangChain framework.
Loading the document for analysis
Begin by establishing a variable to store your API key. This variable will be used subsequently in the code for authentication purposes.
# Hardcoded API key
openai_api_key = "Your API key"It’s a good practice not to hardcode your API key, especially if you intend to share your code with others. For production code that will be distributed, it’s advisable to use environment variables for storing sensitive information like API keys. Next, let’s create a function that loads a document. This function should be capable of loading either a PDF or a text file. If the document provided is neither of these types, the function should raise a ValueError.
def load_document(filename):
if filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents = loader.load()
elif filename.endswith(".txt"):
loader = TextLoader(filename)
documents = loader.load()
else:
raise ValueError("Invalid file type")Once you’ve loaded the documents, you can create a CharacterTextSplitter to segment the loaded content into smaller chunks based on characters.
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=30, separator="\n")
return text_splitter.split_documents(documents=documents)Dividing the document into smaller chunks serves the purpose of creating manageable segments while maintaining some degree of context overlap between them. This approach proves beneficial for various tasks, including text analysis and information retrieval.